Before mixing, the choice of resampler can affect how the tone of the vocals turns out. I'm not familiar with this voice bank, but if the raw samples are high quality, then different resamplers will handle a soft breathy tone differently. I'm personally a fan of tn_fnds, which will turn soft vocals into gentle ones, but others might prefer resamplers that preserve more breathiness. If the noisiness of the vocals comes from the microphone and not from breathiness then I suppose this is less of a factor haha.
The VB specifically is one I made in 2012/2011 and released in 2013 on deviantART, though 1) not many people used her and 2) I unlisted all the videos and didn't release nearly half of her covers (they were bad, but I may relist and upload the remainder on my old YT for archiving). I can almost guarantee that the VB wasn't recorded with a good mic/samples, because if I remember it was either a RockStar (yes, the game) microphone or a karaoke microphone I found in the trash. I'm not familiar with tn_fnds, but as of right now in openUTAU I'm using the Wordline-R and Classic resampler however I do have others: world4utau, fresamp, resampler (+resampler10.dll), and TIPS. Though those other resamplers are old versions that may not be usable, they do seem to
kinda work in UTAU though. I'll try to see if I can find a copy of tn_finds and give that a shot.
Once you get to mixing, handling the high frequencies is a balance between having enough for clarity but not too much that it becomes harsh. A common technique is de-essing, to quiet down the loudest consonant hissing sounds without making everything too quiet. There are dedicated plugins, but you can also just use a multiband compressor. To set the right frequency range, mute the low and high bands temporarily so that you're only hearing the middle band. Sweep the frequency boundaries up and down while listening to the vocals until you can only hear the noisy consonants. Then you can set the compressor settings to compress the loudest consonants down to the level of the other consonants, and unmute the other frequency bands to get the rest of the voice back.
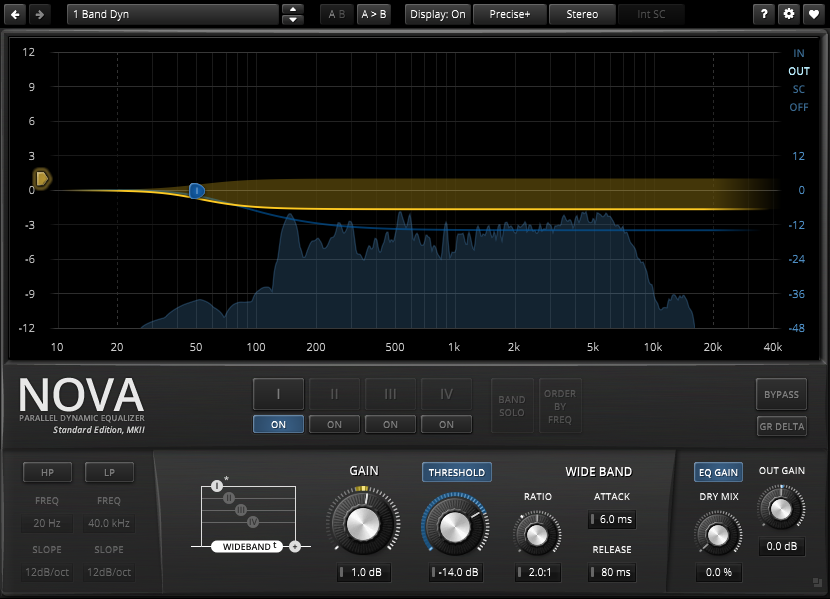
Besides a multiband compressor you can also try using a dynamic equalizer. It looks just like a normal parametric EQ so you might be more familiar with this interface, but instead of lowering all the consonant frequencies by the same amount you can use compression settings to only quiet down the loudest consonants.
ooooOOOOOOOOOKAY, okay. This is definitely something I'm going to look into because this is probably the #1 thing I run into on this bank the most. During audio rendering, I end up just de-amplifying or adding a slight fade in to soften the consonants where I can but this seems a heck of a lot simpler! In all honesty, pretty much everything I've done has been rendered using Audacity with only a few tweaks to the program itself and a few alterations on the baseline stats of some of the presets. But I'm fairly certain I've seen a dynamic equalizer that I can add to the program if it doesn't have something similar already in a newer build (I haven't looked tbch).
Thank you so much for the critique! If you notice anything else please do let me know!

![[K] of Honor](/data/medal/1_1406930084l.jpg)