This tutorial will explain how to record and OTO an ARPAsing bank yourself.
While you can use whatever you like to record, it will be much, much easier to use OREMO. If you're currently unfamiliar with how to use it, see this as an opportunity to learn how. If you plan to do sample processing, you'll have to do it after recording.
Official download: OSDN
Wine wrapper for macOS: UTAForum
Mac native English translation: UTAForum
(I recommend the wine wrapper, because the mac native version doesn't have the comment box.)
To begin, download the latest default reclist from here: http://utaforum.net/resources/arpasing-reclist-directory.299/ You can choose either the version with or without the index. If not using OREMO, the version without the index will be much easier to read.
If you are using the list with the index:
You can record with or without guideBGM. If you want to use guideBGM, I recommend using a short one made for CVVC reclists, such as the CVVChinese BGMs or the VCCV English BGMs.
The comment file will tell you how to pronounce it approximately using words, and precisely in arpabet phonemes. This short article will explain how to read and pronounce arpabet. It's actually pretty straightforward! If you're already familiar with another phonetic system like PaintedCZ's system or X-SAMPA, refer to the chart on this page.
Other than vowel strings, each string only has 1 type of vowel. All three syllables will rhyme.
Sing the 3 syllables consecutively, as if recording VCV. If at any point there is a "q" in the phonetics (or an apostrophe in the words) it means a brief pause (a glottal stop).
For reference, you can download existing voicebanks from the voicebank directory.
FOR MULTIPITCH: The main voicebank folder must contain a pitch that does not have any suffixes. All other pitches must be placed in subfolders. When recording, do not add suffixes to the file names, or Moresampler won't be able to read the index.csv while OTOing.
FOR EXTRA SAMPLES: Any extra samples that aren't standard in ARPAsing must be placed in a subfolder, so that they will have a separate oto.ini file. This enables ARPAsing Assistant to properly read the main oto.ini file with only standard ARPAsing OTO entries.
Onto OTOing! Simply drag and drop the folder onto moresampler.exe to do so.
Enter 3 to choose ARPAsing. When prompted on renaming duplicates, enter y or yes. Whenever there are multiple of the same diphone, such as [s t], this will add a numeric suffix to the end of additional copies. This serves to distinguish each one from the other, as they may sound different based on the context of nearby phonemes in the string. You can also choose whether or not to include a suffix. It's not possible to use characters such as arrows or kanji, so you will have to use suffixes such as "S" or "A#3".
If you are using Mac or Linux, you will have to use wine to run Moresampler. Open terminal in the folder that moresampler.exe is in, and type "wine moresampler.exe /path/to/voicebank". If you're unable to do this, transfer your files to a windows computer, or ask a friend with Windows for help to generate it.
Now that your base OTO is generated, it's time to refine it. Every entry of the OTO is a diphone, meaning that there are only two phonemes or two sounds. In general, the first one is a connector to the previous note, while the second one is the main phoneme for the current note. To OTO, first find the section corresponding to the first phoneme, then find the section for the second phoneme.
First Phoneme
This covers the blue offset and overlap.
[-]
The amount of overlap really doesn't matter for this one, because these notes always come at the beginning of a phrase, right after a rest. The only important thing is that it covers an area of silence.
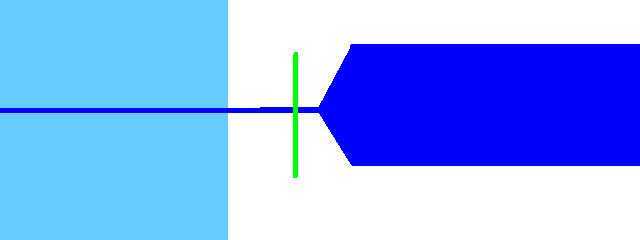
[c]
Unvoiced plosives (p t k)
If this is the first phoneme in the string, move the offset such that the overlap ends up about 15msec before the consonant.
If there are other phonemes before this one, move the offset to where the previous one ended. Make sure you can't hear the previous one. Place the overlap about 15msec before the consonant.
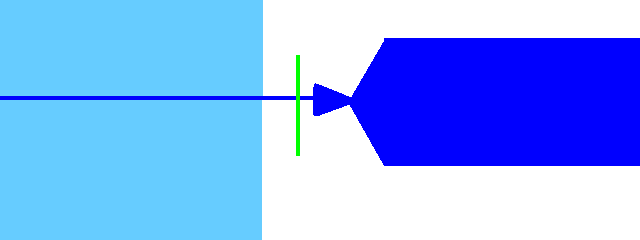
Voiced plosives and affricates (b d g ch jh)
If this is the first phoneme in the string, move the offset such that the overlap ends up where the consonant begins.
If there are other phonemes before this one, move the offset to where the previous one ended. Make sure you can't hear the previous one. Place the overlap where the consonant begins.
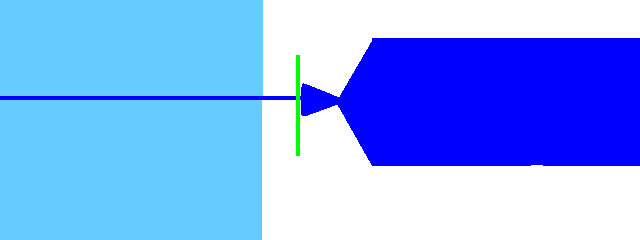
Fricatives, nasals, and liquids (f v th dh s z sh zh hh m n ng l r)
Move the offset to where the consonant begins. For 'r' in particular, you may want to refer to the glides section for help.
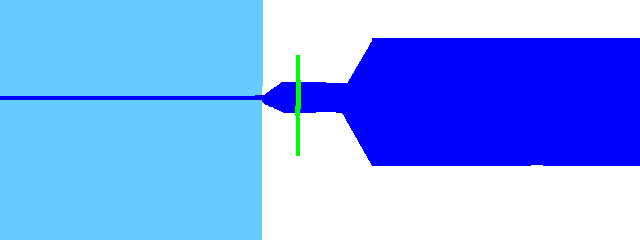
Glides (y w)
These consonants can be difficult to see on a normal waveform. By clicking on the S button, you can switch to spectrogram view, which gives you another way to visualize the audio. The bright areas are the loudest frequencies. These consonants show up as a change in frequencies over time.
Move the offset to where the consonant begins, then place the overlap where it's consistent before the change. The preutterance will end up after the change.


[v]
By default, the overlap for these samples should be at a decently high amount. If it's absurdly small, moving it to around 50msec should be good.
Move the initial offset so that the area between it and the overlap is at a consistent level.
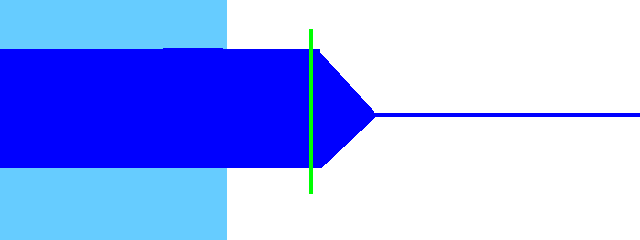
For diphthongs, the overlap should cover the area before the vowel changes.

Second Phoneme
For all cases, the preutterance should be placed where the first phoneme ends and second phoneme begins. This also covers the fixed region, stretched region, and cutoff.
[c]
Stops (p b t d k g ch jh)
There should be a small bit of silence or near silence just before the consonant. Move the fixed region to where the silence begins, and the cutoff to where the silence ends. Yes, we're not including the consonant itself. That's because, in a UST, this note would be followed by another note that DOES have the consonant. This allows for a smooth transition without an awkward double consonant sound.
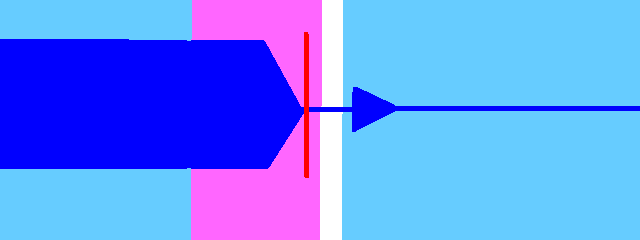
Fricatives (f v th dh s z sh zh hh)
Cover the entire consonant with the fixed region until just before the end. Bring the cutoff to the same place, leaving a tiny gap. Without this gap, resamplers won't be able to render it. However, we don't want these consonants to be stretched.
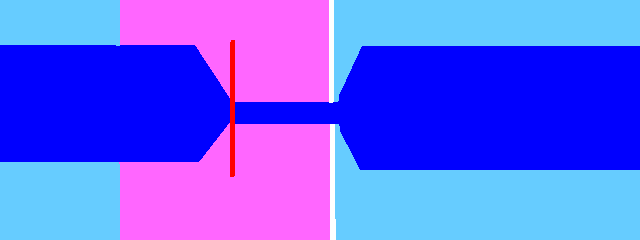
If there is silence after the consonant, have the white area be silence instead.
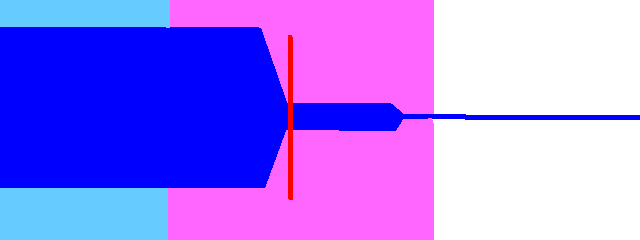
Nasals, liquids and glides (m n ng l r y w)
Move the fixed region to where the consonant starts being stable and consistent. Use the cutoff to remove where the consonant ends or fades out. These consonants are safe to stretch.
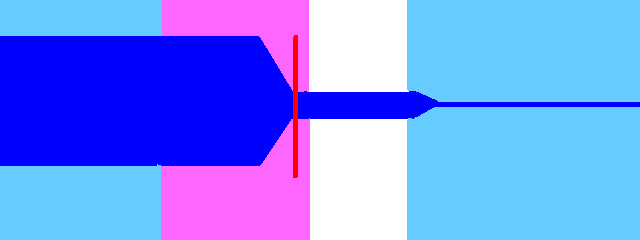
[v]
Move the fixed region up to where the vowel starts being stable and consistent. Use the cutoff to remove where the vowel fades out. The white area will be the sustained part of the note, which ensures that it will sound good.

For vowel-vowel diphones, place the preutterance at the end of the vowel change.

For diphthongs, place the cutoff before the vowel changes.

[-]
Cover everything with the fixed region, such that everything in white is silence.

And just like that, your voicebank is already done. Have fun, good luck! Feel free to ask any questions in the discussion thread.
While you can use whatever you like to record, it will be much, much easier to use OREMO. If you're currently unfamiliar with how to use it, see this as an opportunity to learn how. If you plan to do sample processing, you'll have to do it after recording.
Official download: OSDN
Wine wrapper for macOS: UTAForum
Mac native English translation: UTAForum
(I recommend the wine wrapper, because the mac native version doesn't have the comment box.)
To begin, download the latest default reclist from here: http://utaforum.net/resources/arpasing-reclist-directory.299/ You can choose either the version with or without the index. If not using OREMO, the version without the index will be much easier to read.
If you are using the list with the index:
- The folder contains a reclist file, OREMO comment file, and index file.
- The reclist is numbers 000 to 334.
- The OREMO comment file allows you to see the actual phonemes or words that correspond with each number.
- The index file is for moresampler to reference when generating the OTO.
- The folder contains a reclist file and OREMO comment file.
- The reclist contains arpabet phonemes.
- The OREMO comment file allows you to see the words that correspond with the phonemes.
- No index file is necessary, because moresampler can read the file names as-is.
You can record with or without guideBGM. If you want to use guideBGM, I recommend using a short one made for CVVC reclists, such as the CVVChinese BGMs or the VCCV English BGMs.
The comment file will tell you how to pronounce it approximately using words, and precisely in arpabet phonemes. This short article will explain how to read and pronounce arpabet. It's actually pretty straightforward! If you're already familiar with another phonetic system like PaintedCZ's system or X-SAMPA, refer to the chart on this page.
Other than vowel strings, each string only has 1 type of vowel. All three syllables will rhyme.
Sing the 3 syllables consecutively, as if recording VCV. If at any point there is a "q" in the phonetics (or an apostrophe in the words) it means a brief pause (a glottal stop).
For reference, you can download existing voicebanks from the voicebank directory.
FOR MULTIPITCH: The main voicebank folder must contain a pitch that does not have any suffixes. All other pitches must be placed in subfolders. When recording, do not add suffixes to the file names, or Moresampler won't be able to read the index.csv while OTOing.
FOR EXTRA SAMPLES: Any extra samples that aren't standard in ARPAsing must be placed in a subfolder, so that they will have a separate oto.ini file. This enables ARPAsing Assistant to properly read the main oto.ini file with only standard ARPAsing OTO entries.
Onto OTOing! Simply drag and drop the folder onto moresampler.exe to do so.
Enter 3 to choose ARPAsing. When prompted on renaming duplicates, enter y or yes. Whenever there are multiple of the same diphone, such as [s t], this will add a numeric suffix to the end of additional copies. This serves to distinguish each one from the other, as they may sound different based on the context of nearby phonemes in the string. You can also choose whether or not to include a suffix. It's not possible to use characters such as arrows or kanji, so you will have to use suffixes such as "S" or "A#3".
If you are using Mac or Linux, you will have to use wine to run Moresampler. Open terminal in the folder that moresampler.exe is in, and type "wine moresampler.exe /path/to/voicebank". If you're unable to do this, transfer your files to a windows computer, or ask a friend with Windows for help to generate it.
Now that your base OTO is generated, it's time to refine it. Every entry of the OTO is a diphone, meaning that there are only two phonemes or two sounds. In general, the first one is a connector to the previous note, while the second one is the main phoneme for the current note. To OTO, first find the section corresponding to the first phoneme, then find the section for the second phoneme.
First Phoneme
This covers the blue offset and overlap.
[-]
The amount of overlap really doesn't matter for this one, because these notes always come at the beginning of a phrase, right after a rest. The only important thing is that it covers an area of silence.
[c]
Unvoiced plosives (p t k)
If this is the first phoneme in the string, move the offset such that the overlap ends up about 15msec before the consonant.
If there are other phonemes before this one, move the offset to where the previous one ended. Make sure you can't hear the previous one. Place the overlap about 15msec before the consonant.
Voiced plosives and affricates (b d g ch jh)
If this is the first phoneme in the string, move the offset such that the overlap ends up where the consonant begins.
If there are other phonemes before this one, move the offset to where the previous one ended. Make sure you can't hear the previous one. Place the overlap where the consonant begins.
Fricatives, nasals, and liquids (f v th dh s z sh zh hh m n ng l r)
Move the offset to where the consonant begins. For 'r' in particular, you may want to refer to the glides section for help.
Glides (y w)
These consonants can be difficult to see on a normal waveform. By clicking on the S button, you can switch to spectrogram view, which gives you another way to visualize the audio. The bright areas are the loudest frequencies. These consonants show up as a change in frequencies over time.
Move the offset to where the consonant begins, then place the overlap where it's consistent before the change. The preutterance will end up after the change.
[v]
By default, the overlap for these samples should be at a decently high amount. If it's absurdly small, moving it to around 50msec should be good.
Move the initial offset so that the area between it and the overlap is at a consistent level.
For diphthongs, the overlap should cover the area before the vowel changes.
Second Phoneme
For all cases, the preutterance should be placed where the first phoneme ends and second phoneme begins. This also covers the fixed region, stretched region, and cutoff.
[c]
Stops (p b t d k g ch jh)
There should be a small bit of silence or near silence just before the consonant. Move the fixed region to where the silence begins, and the cutoff to where the silence ends. Yes, we're not including the consonant itself. That's because, in a UST, this note would be followed by another note that DOES have the consonant. This allows for a smooth transition without an awkward double consonant sound.
Fricatives (f v th dh s z sh zh hh)
Cover the entire consonant with the fixed region until just before the end. Bring the cutoff to the same place, leaving a tiny gap. Without this gap, resamplers won't be able to render it. However, we don't want these consonants to be stretched.
If there is silence after the consonant, have the white area be silence instead.
Nasals, liquids and glides (m n ng l r y w)
Move the fixed region to where the consonant starts being stable and consistent. Use the cutoff to remove where the consonant ends or fades out. These consonants are safe to stretch.
[v]
Move the fixed region up to where the vowel starts being stable and consistent. Use the cutoff to remove where the vowel fades out. The white area will be the sustained part of the note, which ensures that it will sound good.
For vowel-vowel diphones, place the preutterance at the end of the vowel change.
For diphthongs, place the cutoff before the vowel changes.
[-]
Cover everything with the fixed region, such that everything in white is silence.
And just like that, your voicebank is already done. Have fun, good luck! Feel free to ask any questions in the discussion thread.
