
A comprehensive guide on writing base configuration files (otos) for Classic UTAU and OpenUTAU. Also applicable to DIY synths that use the same configuration parameters. This resource assumes at least a basic knowledge of UTAU.
This tutorial is crossposted from my website. Part 1 covers making bases from scratch and Part 3 covers making bases using regular expressions.
Making Bases from Existing OTOs
AKA, how to calculate the average values of an oto.ini and use them to make a base. This does not require actual math on your part.
I recommend still following the previous section in terms of setting up the first string of the oto (or a placeholder string) and then duplicating and modifying it for each of the following strings of the same type, rather than going through and setting the averaged values for every string manually.
This is also a good way to check how accurate an existing base oto is; see the bottom of this page for instructions on how to easily modify or update an existing base.
You will need:
Setting Up the Spreadsheet
First, open the fully configured oto.ini in your text editor.
Now, we want to get the oto into a format where every value will be placed in a different cell of a spreadsheet. There are two ways to accomplish this, but both have the same end result.
CSV Method
Shout out to slashhearts for suggesting this method.
CSV starts for "comma separate value"; it is a type of text file that will read each comma as, well, a separator. Handy for us then that the oto.ini already does this.
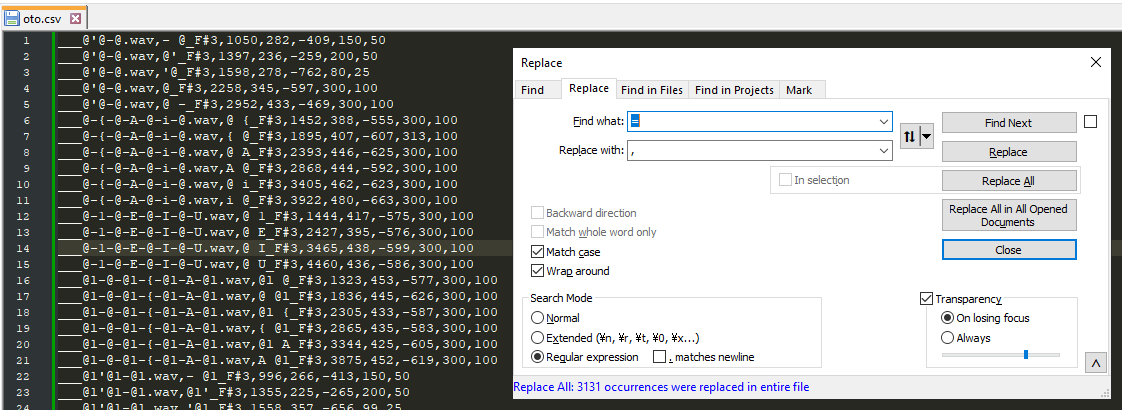
We will want to separate our aliases, too, however, but this can be done by opening the Find and Replace menu (<CTRL+H>) and replacing [=] with [,] in the entire file.
Next, save the file as something like oto.csv, and open the newly created .csv file in your spreadsheet editor.
Tab Method
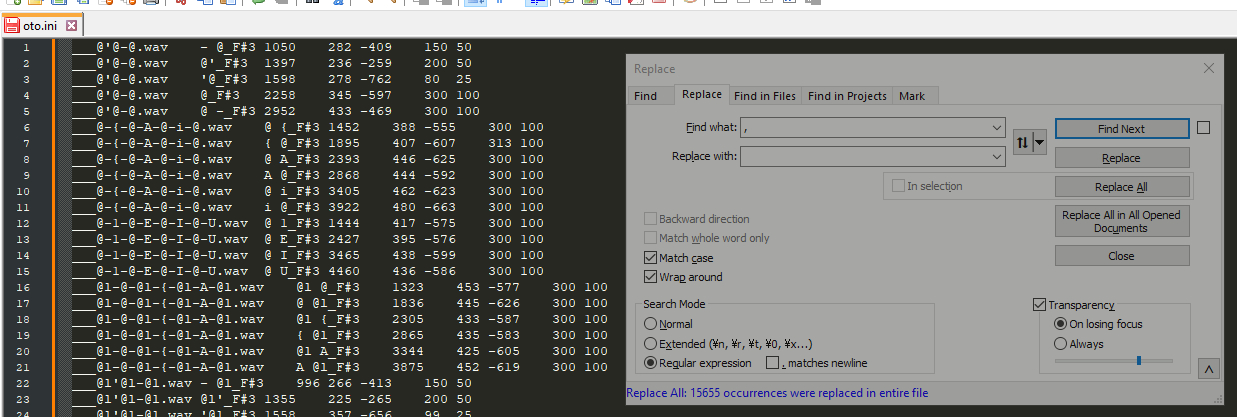
This method involves finding and replacing all of the commas in the oto with a tab character.
Open up the Find and Replace menu (<CTRL+H>), find [,] and replace with a tab (you may need to copypaste it into the box). Next, find [=] and replace it with tab as well.
Now, create a new file in your spreadsheet editor. Select the entire contents of the edited oto (<CTRL+A>) and copypaste them into the blank sheet.
Regardless of which method was used, we should now have a spreadsheet that looks something like this:
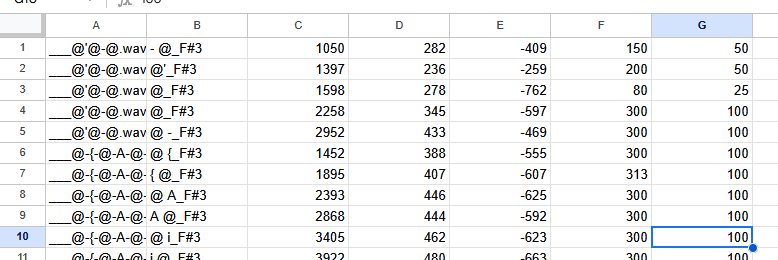
If we have different types of strings, the next step is to separate them by string type. In this reclist, this is already done thanks to the different string prefixes, but that might not always be the case. I'll use the CVVC strings for this demonstration, so I separated them into their own page of the spreadsheet.
If we have different types of samples within the same string, as we do here, we'll also want to separate those from each other. It wouldn't be very useful to average, say, the values of a CV and VC together. This is why we separated the aliases into their own cells, as this makes sorting them by sample type easier.
Select the column with the aliases in it, right click, and select Sort sheet A to Z. I'm working in Google Sheets, but this process should be similar in other spreadsheet editors.
You'll likely still have to do a little bit of manual sorting by dragging the rows around, but this should speed up the process. I separate the sample groups with a few empty rows for visibility. You can also move like-samples to their own spreadsheet pages if it makes it easier for you.
Calculating Most Averages
Now comes the calculations. For every parameter except the offset, we can get one big average value using every sample of the same type. To do this, create an empty row underneath the last sample, and enter this formula into the cells corresponding to the consonant, cutoff, preutterance, and overlap:
Where [N] represents the current column letter, [X] represents the first row of the range, and [Y] represents the last row of the range.
It can also be useful to calculate the median value to make sure the average isn't being thrown off by outliers.
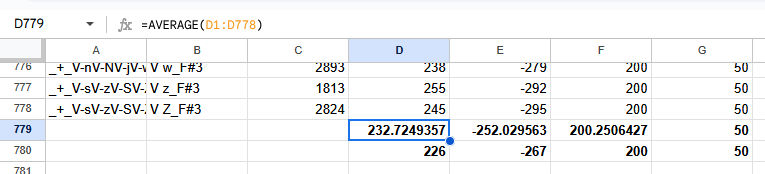
In our case, they're pretty comparable, which is a good sign that our oto is consistent. We could plug these values into our base exactly as they are, but this would only representative of one speaker's production, so it can be better to round them to "nicer" values. We can do that by creating a new row underneath our average and entering this formula:
To round the average values to, say, the nearest 25 milliseconds, we end up with something like this:

Thus, the VCs in our base oto would end up with these values, which you might notice are the same as the ones I recommended if building a base from scratch:
Calculating Average Offsets
Finally, let's figure out our offsets. Since these will be different depending on which syllable in the string a sample is being taken from, we'll need to organize our samples by this.
To do this, select all the rows in the spreadsheet corresponding to the sample type we're looking at, right click on the selection, and navigate to View more cell actions > Sort range.
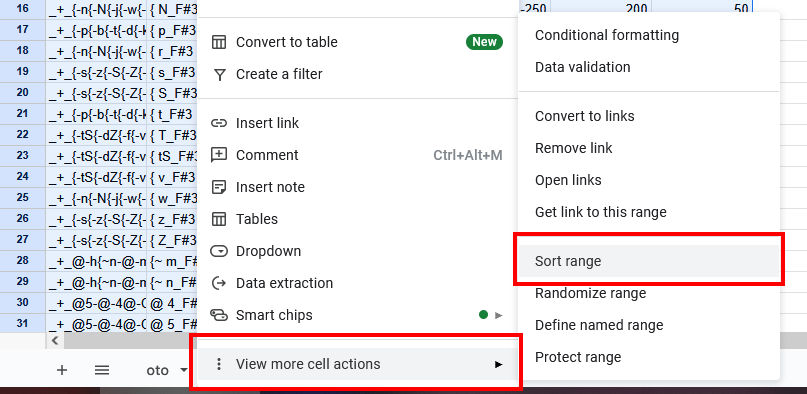
In this menu, select the column that corresponds to the offset value and sort it A to Z. Again, this process might not be exactly the same in other spreadsheet editors, but should be similar.
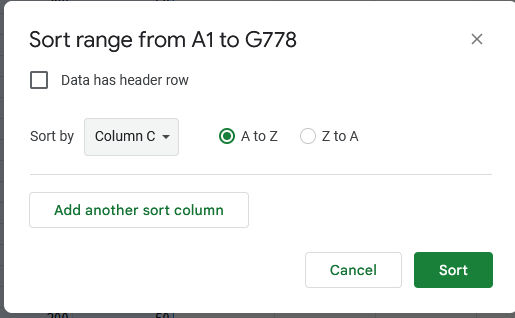
Now our samples should be more-or-less organized by which syllable they're taken from, and we can repeat the averaging process for each group of them. Where to split the groups should be somewhat obvious by a sudden spike in the offset value by a few hundred milliseconds.
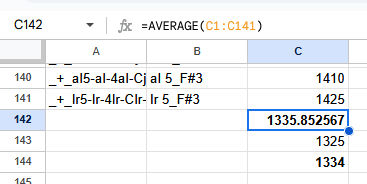
Next, let's compare the average offsets of each syllable position. In my case, I've ended up with [1336], [1860], [2344], [2864], [3362], and [3863]. As expected, the initial offset hits at around 200 ms (the length of the preutterance) less than the position of fourth beat (the second syllable of a string preceded by 2 beats of rest) and each offset is roughly 500 ms apart (the duration of 1 beat at 120 BPM).
Most of these values MROUND to ending in 50, so let's use that for our base value.
Putting it altogether, we get the following base values for our VCs:
These are pretty close to the base offset values we calculated manually, but should be more accurate on the whole. You may also notice that these values are the same as what I use in my own CVVC base otos, and this is exactly how I calculated them.
If we want to be even more precise, we could run these calculations separately for consonants with different manners of articulation, like taps which are quite short versus sibilants which are a bit longer than average, but taking a broad average is usually good enough for a base.
Modifying Base OTOs
If you want to modify an existing base oto, whether because you've just averaged your values and found more precise numbers to use, because you want to record at a different tempo than a base is set up for, or some other reason, the process is pretty straightforward.
Basically, you can just find and replace the values you want to change. Be careful not to get unintented lines of the oto caught in the crossfire, but usually matching and replacing all of the numerical values of the line isn't likely to match unintended samples.
For example, matching all instances of [225,-250,200,50] will affect the consonant, cutoff, preutterance, and overlap, of the VCs in the previous examples, but is not likely to match with those parameters on any unintended sample. So if we want to, say, change the preutterance to 300 (and subsequently the other oto values), we could enter [325,-350,300,100] in the replace field.
This tutorial is crossposted from my website. Part 1 covers making bases from scratch and Part 3 covers making bases using regular expressions.
Making Bases from Existing OTOs
AKA, how to calculate the average values of an oto.ini and use them to make a base. This does not require actual math on your part.
I recommend still following the previous section in terms of setting up the first string of the oto (or a placeholder string) and then duplicating and modifying it for each of the following strings of the same type, rather than going through and setting the averaged values for every string manually.
This is also a good way to check how accurate an existing base oto is; see the bottom of this page for instructions on how to easily modify or update an existing base.
You will need:
- A fully configured oto.ini from an existing voicebank.
- A text editor. The default Notepad app will work fine, but one which is able to use regular expressions (regex) and which will allow you to change the character encoding is more efficient. For Windows users, I recommend Notepad++; it's free, open source, and easy to use.
- A spreadsheet editor with built-in formulas, like Microsoft Excel, Google Sheets, or LibreOffice Calc.
Setting Up the Spreadsheet
First, open the fully configured oto.ini in your text editor.
Now, we want to get the oto into a format where every value will be placed in a different cell of a spreadsheet. There are two ways to accomplish this, but both have the same end result.
CSV Method
Shout out to slashhearts for suggesting this method.
CSV starts for "comma separate value"; it is a type of text file that will read each comma as, well, a separator. Handy for us then that the oto.ini already does this.
We will want to separate our aliases, too, however, but this can be done by opening the Find and Replace menu (<CTRL+H>) and replacing [=] with [,] in the entire file.
Next, save the file as something like oto.csv, and open the newly created .csv file in your spreadsheet editor.
Tab Method
This method involves finding and replacing all of the commas in the oto with a tab character.
Open up the Find and Replace menu (<CTRL+H>), find [,] and replace with a tab (you may need to copypaste it into the box). Next, find [=] and replace it with tab as well.
Now, create a new file in your spreadsheet editor. Select the entire contents of the edited oto (<CTRL+A>) and copypaste them into the blank sheet.
Regardless of which method was used, we should now have a spreadsheet that looks something like this:
If we have different types of strings, the next step is to separate them by string type. In this reclist, this is already done thanks to the different string prefixes, but that might not always be the case. I'll use the CVVC strings for this demonstration, so I separated them into their own page of the spreadsheet.
If we have different types of samples within the same string, as we do here, we'll also want to separate those from each other. It wouldn't be very useful to average, say, the values of a CV and VC together. This is why we separated the aliases into their own cells, as this makes sorting them by sample type easier.
Select the column with the aliases in it, right click, and select Sort sheet A to Z. I'm working in Google Sheets, but this process should be similar in other spreadsheet editors.
You'll likely still have to do a little bit of manual sorting by dragging the rows around, but this should speed up the process. I separate the sample groups with a few empty rows for visibility. You can also move like-samples to their own spreadsheet pages if it makes it easier for you.
Calculating Most Averages
Now comes the calculations. For every parameter except the offset, we can get one big average value using every sample of the same type. To do this, create an empty row underneath the last sample, and enter this formula into the cells corresponding to the consonant, cutoff, preutterance, and overlap:
Code:
=AVERAGE(NX:NY)Where [N] represents the current column letter, [X] represents the first row of the range, and [Y] represents the last row of the range.
It can also be useful to calculate the median value to make sure the average isn't being thrown off by outliers.
In our case, they're pretty comparable, which is a good sign that our oto is consistent. We could plug these values into our base exactly as they are, but this would only representative of one speaker's production, so it can be better to round them to "nicer" values. We can do that by creating a new row underneath our average and entering this formula:
Code:
=MROUND(number, factor)To round the average values to, say, the nearest 25 milliseconds, we end up with something like this:
Note said:
Thus, the VCs in our base oto would end up with these values, which you might notice are the same as the ones I recommended if building a base from scratch:
Code:
[file_name].wav=V C,[offset],225,-250,200,50Calculating Average Offsets
Finally, let's figure out our offsets. Since these will be different depending on which syllable in the string a sample is being taken from, we'll need to organize our samples by this.
To do this, select all the rows in the spreadsheet corresponding to the sample type we're looking at, right click on the selection, and navigate to View more cell actions > Sort range.
In this menu, select the column that corresponds to the offset value and sort it A to Z. Again, this process might not be exactly the same in other spreadsheet editors, but should be similar.
Now our samples should be more-or-less organized by which syllable they're taken from, and we can repeat the averaging process for each group of them. Where to split the groups should be somewhat obvious by a sudden spike in the offset value by a few hundred milliseconds.
Next, let's compare the average offsets of each syllable position. In my case, I've ended up with [1336], [1860], [2344], [2864], [3362], and [3863]. As expected, the initial offset hits at around 200 ms (the length of the preutterance) less than the position of fourth beat (the second syllable of a string preceded by 2 beats of rest) and each offset is roughly 500 ms apart (the duration of 1 beat at 120 BPM).
Most of these values MROUND to ending in 50, so let's use that for our base value.
Putting it altogether, we get the following base values for our VCs:
Code:
[file_name].wav=V C1,1350,225,-250,200,50
[file_name].wav=V C2,1850,225,-250,200,50
[file_name].wav=V C3,2350,225,-250,200,50
[file_name].wav=V C4,2850,225,-250,200,50
[file_name].wav=V C5,3350,225,-250,200,50
[file_name].wav=V C6,3850,225,-250,200,50These are pretty close to the base offset values we calculated manually, but should be more accurate on the whole. You may also notice that these values are the same as what I use in my own CVVC base otos, and this is exactly how I calculated them.
If we want to be even more precise, we could run these calculations separately for consonants with different manners of articulation, like taps which are quite short versus sibilants which are a bit longer than average, but taking a broad average is usually good enough for a base.
Modifying Base OTOs
If you want to modify an existing base oto, whether because you've just averaged your values and found more precise numbers to use, because you want to record at a different tempo than a base is set up for, or some other reason, the process is pretty straightforward.
Basically, you can just find and replace the values you want to change. Be careful not to get unintented lines of the oto caught in the crossfire, but usually matching and replacing all of the numerical values of the line isn't likely to match unintended samples.
For example, matching all instances of [225,-250,200,50] will affect the consonant, cutoff, preutterance, and overlap, of the VCs in the previous examples, but is not likely to match with those parameters on any unintended sample. So if we want to, say, change the preutterance to 300 (and subsequently the other oto values), we could enter [325,-350,300,100] in the replace field.
